
Creating and Using Microsoft Fabric Lakehouse

This post aims to demonstrate how easy it is to use Lakehouse in Microsoft Fabric for data processing. In general, a data lakehouse represents a modern approach that combines the advantages of data lakes and data warehouses. It supports high-scale BI and machine learning while providing transactional support for both structured and unstructured data.
I am planning to share/capture my learnings in a beginner friendly blog posts covering Fabric features and functionalities. This can serve as a helpful reference for me and other like-minded learners of Microsoft Fabric. Appreciate your comments/views in case if anything represented incorrectly.
In Microsoft terms, Fabric Lakehouse is a data architecture platform for storing, managing, and analyzing structured and unstructured data in a single location. It provides a flexible and scalable solution that allows organizations to handle large volumes of data using various tools and frameworks for processing and analysis. Below are the key terms and approaches employed in the Fabric Lakehouse.
Delta Lake: In a Fabric lakehouse, data is stored in highly scalable file storage format in a OneLake store and a relational objects such as tables and views based on the open source Delta Lake format. It is applied as a metadata layer so that they can be queried using SQL. Delta Lake is the optimized storage layer that provides the foundation for tables in a lakehouse with file-based transaction log that can be used by any system for reading and processing. All tables on lackhouse are Delta tables by default. Delta Transaction Log Protocol
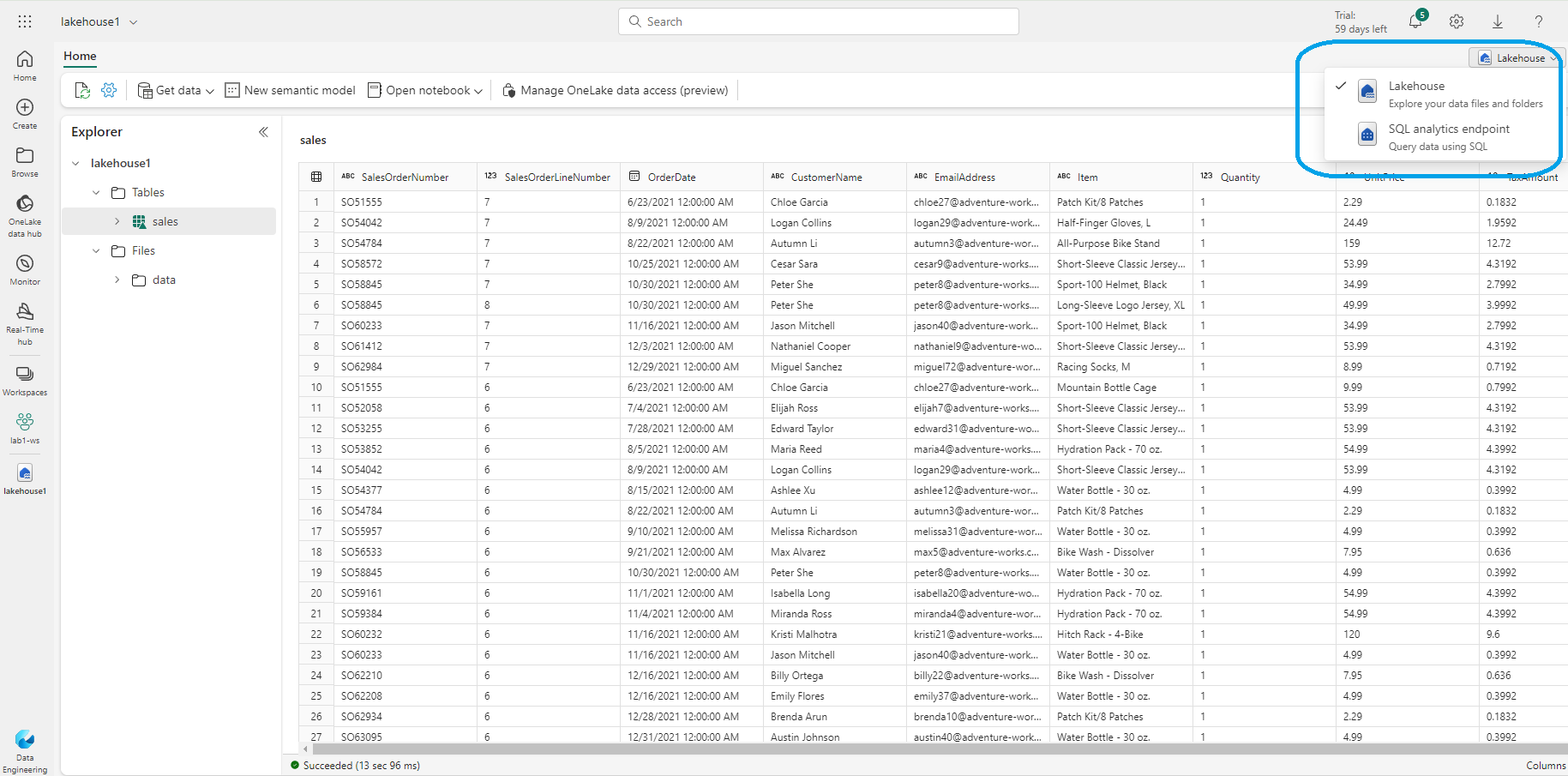
SQL analytics Endpoint: Fabric provides a SQL-based experience for lakehouse Delta tables called the SQL analytics endpoint. It helps analye data using SQL, save functions and views that can be accessed by switching to SQL analytics endpoint in the Lakehouse explorer. Creating a lakehose automatically creates a SQL analytics endponit that points to the Delta table in created lakehouse. Every Lakehouse has one SQL analytics endpoint, and each workspace can have more than one Lakehouse.
Intracting with a lakehouse and the data within it can be done through the following ways.
- Lakehouse explore provides an interface to users for data navigation, access and handling with three sections such us a Table section, Unidentified Area and File section.
- Notebooks allows users to write code, transform and write directly to Lakehouse as tables and/or folders. Fabric lakehouse with a notebook supports Spark API and Pandas API for these operation.
- Pipelines provides data integration utilities such as pipeline copy tool to pull data from other sources into the Lakehouse.
- Apache Spark job definitions is a Microsoft Fabric code item that allows you to submit batch/streaming jobs to Spark clusters.
- Dataflows Gen 2 assist in getting and transforming the data from various data sources and publish the dataflow.
Creating and Using Lakehouse: A lakehouse can be created after creating a workspace in Fabric by selecting Synapse Data Engineering.
Fabric Lakehouse Explorer View:
Enables you to explore tables and files.
- Tables folders includes tables that can be queried using SQL. These tables are based on Delta lake file format as explained.
- Files folder contains files for the lakehouse uploaded by the user.
- Upload: Files can be uploaded by selecting Upload > Upload File in the Files folder. Uploaded files can be validated by using the preview option.
- Shortcuts can be created to reference data that is stored externally.
- Load to Table allows to load the data from the uploaded file into a table to query it using SQL.
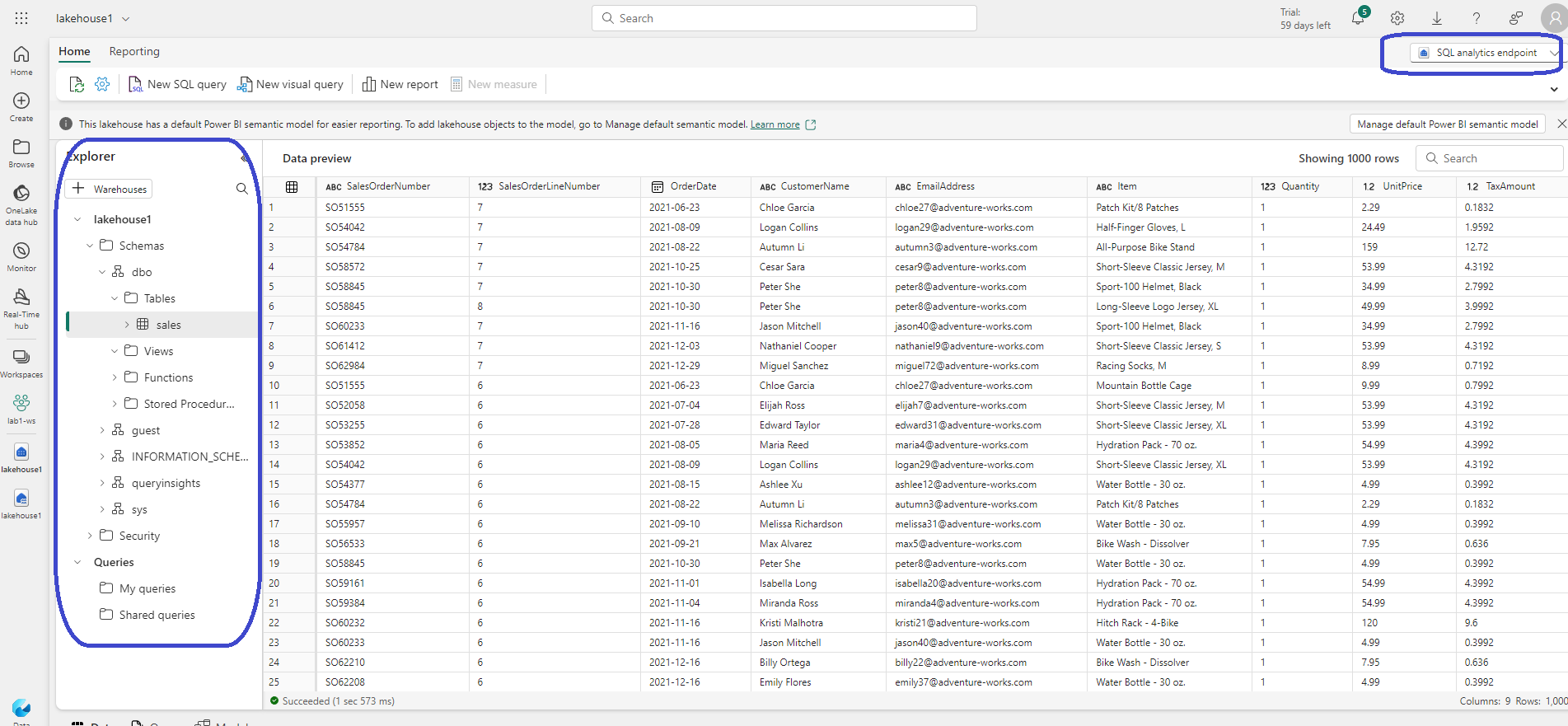
SQL analytics Endpoint View:
Through the SQL analytics endpoint tables can be queried using SQL statements.
- New SQL Query provides the interface to write and execute SQL statements.
- Create a visual query provides Power BI experience to apply Power Query approach for managing coloumns and transform operations.
- New Report allows tables in your lakehouse are automatically added to a default semantic model for reporting with Power BI. Provides the Power BI experience for report/dashboard creation.
We will review features like using Apache Spark for processing data from files and Delta Lake tables in Lakehouse in the upcoming posts.
Related Readings:
